When conducting scientific research, the use of statistical methods of analysis is of particular importance in order to effectively interpret the information collected. Regardless of the data being analyzed, whether it is the distribution of baseline clinical parameters for a sample or instrumental data collected from repeated measurements, the use of statistics allows for quality and reliable processing. Statistical data analysis is critical to academic work because the conclusions of a study ultimately depend on how well and reliably the data have been processed. A situation in which, for example, the effects of the COVID-19 vaccine on patients were measured, but the data were not processed correctly and, as a result, the conclusions were invalid, must be ruled out because it entails a severe public health risk. This essay discusses in detail the two levels of statistical research associated with descriptive data processing methods and more in-depth measurements, which are impossible to obtain from looking at measures of central tendency alone. The essence of the essay boils down to a comparative analysis between descriptive and inferential statistics and a review of their application to clinical practice.
Statistical techniques used for academic research and analysis in other fields include many techniques. More specifically, these may consist of calculating the mean and standard deviation, the median, and the mode and may also include statistical hypothesis testing with parametric and non-parametric tests, depending on the sample size and type of data used. However, these many different tests can be formally divided into two levels of data analytics, namely descriptive and inferential. Both terms should be defined first in order to make them more meaningful.
Descriptive statistics should be understood as a literal interpretation of the term; descriptive statistics describe a data set or distribution. This level of statistic clarifies trends in the overall data set or population and allows for initial assumptions to be made based on its results (George & Mallery, 2018). For example, if nurse practitioner job satisfaction was used as a measure, descriptive statistics create mean, median, and mode values for that distribution. From this data, the overall patterns of the data set, including mean job satisfaction, can be postulated. However, measures of central tendency do not allow us to judge the variance of the sample data, so measures of scattering, including variances, standard deviations, and quartiles, are often used.
Descriptive statistics turn out to be broader since they can also be implemented using frequency tables and cross-tabulations. Such procedures still do not allow for the discovery of causal relationships and hypothesis testing, but they provide valuable information about response trends. For example, with cross-tabulation, it becomes possible to generate inferences like the following: “20% of DNPs responded that…”. Meanwhile, descriptive analysis operates on sample data to create generalizable conclusions for them. In essence, descriptive analysis is similar to cross-sectional studies — because, in such studies, the methodological basis is a description — in which the goal is to examine a slice of data from a specific sample at a specific time. The descriptive analysis does the same: it uses sample data to describe, generalize, and postulate patterns in that sample: it does not imply a shift to a population distribution because descriptive analysis has no probabilistic tools for extrapolation. In other words, if it is known for a sample that 20% of nurses experienced chronic stress, then these data cannot be extrapolated to the population without inferential statistical procedures. However, while descriptive statistics are broadly possible to elucidate patterns in a data set, its use does not respond to deep data analytics and does not accurately explore cause and effect.
For this reason, the use of another, more profound level of statistical analysis is necessary for academic work. Concerning inferential statistics, it is proper to emphasize the absence of a universal definition that fully describes the ideational essence of this level. On the one hand, inferential statistics focuses on hypothesis testing and searching for causal patterns among variables (Cooksey, 2020). On the other hand, inferential statistics take a non-descriptive look at the data presented to extrapolate to the population (McGregor, 2018). In either case, this type of statistical analysis provides a more in-depth but less accurate mode of data processing. The lower accuracy of inferential statistics stems from its reliance on probabilistic principles. Since it is never possible to accurately scale results from a sample to a population, there are always some assumptions to statistically assume that this extrapolation is possible. Regarding hypothesis testing, appropriate tests use a critical level alpha parameter, which determines whether a null hypothesis can be rejected or accepted. In simple words, this critical level creates an allowed possibility for error in the extrapolation of the data to the population.
The use of inferential statistical methods is consistently demonstrated in clinical work. For example, if a study is based on testing the effect of a pill on the clinical condition of therapy, the use of a one-sample t-test can be useful to test for statistically significant differences in mean values between groups (Regoniel, 2020). Meanwhile, if nominal data — ethnicity of patients — are used for evaluation, the use of non-parametric analogues of such tests, including the Friedman test, is appropriate. Inferential statistics procedures are based on postulating hypotheses, null and alternative, and selecting the appropriate test that can be applied to the current data set and target problem. Inferential statistics can be done manually, but modern methods allow automatic calculations, including with MS Excel, IMB SPSS, Tableau or other alternative platforms.
In other words, the difference between descriptive and inferential statistics stems primarily from the task they are designed to accomplish: to summarize data or to extend findings to a population. Figure 1 below is a Venn diagram that allows us to define more precisely the difference between the two levels of data analytics. As should be clarified, inferential statistics are essentially secondary in that they use — automatically or manually by the author — the results of descriptive statistics, whereas descriptive statistics do not need data from other analyses and can operate on sample data at once. The secondary nature of the inferential analysis is determined by hypotheses that are postulated on the fact of descriptive statistics: for example, comparisons of means or frequencies between groups. At the same time, inferential statistics are significantly broader, as they offer multiple levels of hypothesis testing. For example, while descriptive statistics reported the mean and standard deviation, inferential procedures allow for parametric tests and for determining the statistical significance of differences and then post hoc tests to test the location of such differences. It is also worth emphasizing that descriptive statistics are more objective and neutral because they do not involve the selection of a specific test for testing; instead, descriptive statistics only summarize the available data. Inferential statistics, on the other hand, are associated with generating conclusions for each analysis, allowing one to accept or reject hypotheses — the choice of a particular test, the choice of significance level, and even the postulation of a hypothesis may determine the results, which makes inferential statistics less neutral. However, one should not give preference to only one of the levels because, in truly high-quality academic papers, both types of statistics are harmonized to form more comprehensive results.
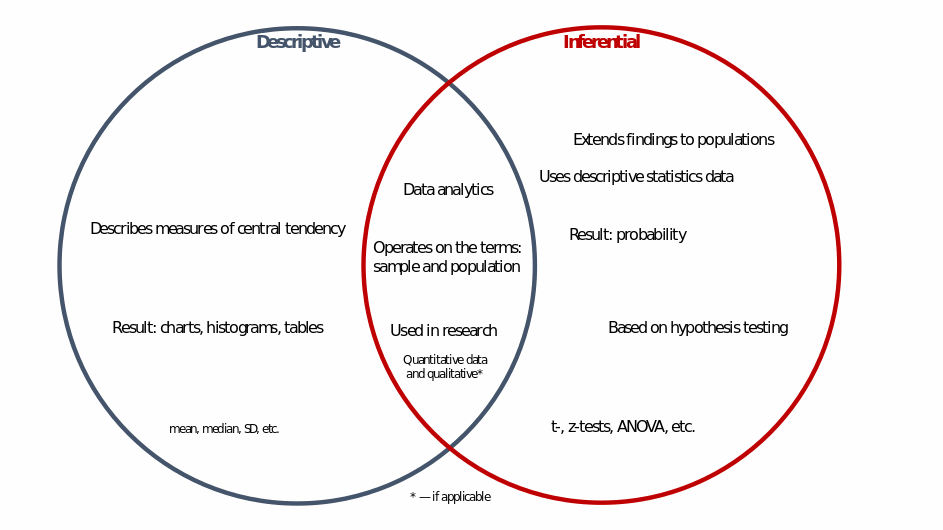
In conclusion, it is worth emphasizing that statistical analysis is actively used to process the data collected, whether quantitative or qualitative. Data analytics consists of a myriad of methods and techniques, each of which is applicable in specific cases. For instance, for categorical variables — respondent name — using a mean value makes no sense, but using a frequency distribution allows to generalize the data. Various statistical methods are divided into descriptive and inferential statistics: the former allows us to describe and summarize data, while the latter allows us to create inferences and extrapolate results to the population. As has been shown, each of these levels is associated with unique features that qualitatively distinguish the descriptive level of analysis from the inferential level. At the same time, both statistics also reveal apparent similarities. In practice, it is not necessary to choose between the two levels since the tasks set in the studies usually require both descriptive and inferential statistics.
References
Cooksey, R. W. (2020). Illustrating statistical procedures: Finding meaning in quantitative data. Springer.
George, D., & Mallery, P. (2018). IBM SPSS statistics 25 step by step. Routledge.
McGregor, S. (2018). Understanding and evaluating research: A critical guides. SAGE Publications.
Regoniel, P. (2020). Parametric statistics: Four widely used parametric tests and when to use them. Simply Educate. Web.
