Introduction
This report was commissioned by the CEO of Pan National Real Estate Company. The report aims at developing a quantitative model that can be used to predict the prices of houses based on their area in square feet. This model will be then used to determine a benchmark price for the company to list the houses in the following year. Thus, the primary research questions this paper aims at answering is “what is the benchmark price Pan National Real Estate should use to list houses based on the area of the houses?” In order to answer this question, the report uses a dataset of 50 randomly selected houses in different parts of the US to create a linear regression model that would provide an equation for pricing the houses.
Utilization of a linear regression model is appropriate when conducting a correlational research. In particular, a regression model is appropriate when a linear relationship is expected between the predictor (x) variables and the outcome (y) variable. A regression model is appropriate when a scatterplot looks like a collection of dots scattered around a straight line that is either ascending or descending. A predictor variable is an independent variable that affects the dependent variable if manipulated. Price of a real estate object is expected to be dependent of its area. Therefore, the area in square feet was used a predictor variable, while the price of a house was selected as a dependent variable.
Data Collection
A dataset of 1000 houses was used to develop a quantitative model to answer the research question. Microsoft Excel was used to create a new column with a random number, sort the list of entries based on the random number, then choose the first 50 entries to create a random sample of 50 entries. The random numbers were assigned using randbetween(1; 1000) command. The price of a property was chosen as the dependent variable, and the area in square feet was utilized as the predictor variable. The data is visualized in a scatterplot provided in Figure 1 below.
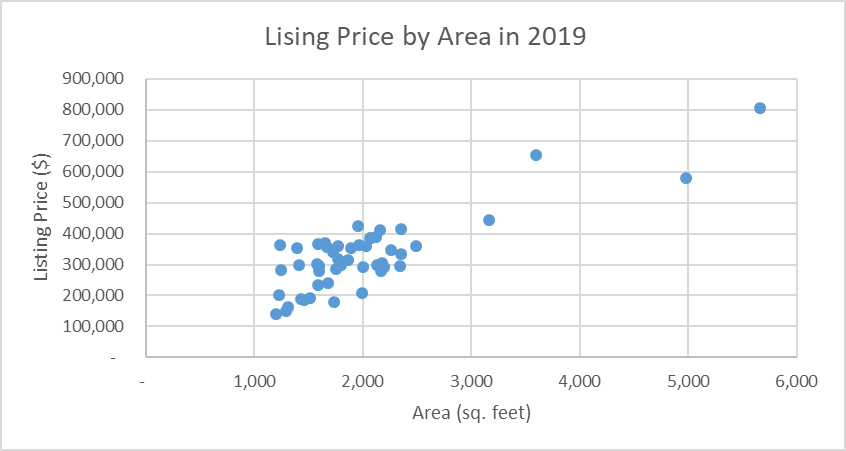
The scatterplot demonstrates that the data points a scattered along an ascending line, which is a sign of a positive linear correlation. This implies that linear regression is an appropriate method for developing a forecasting model.
Data Analysis
Before conducting inferential analysis, it is beneficial to provide a summary of variables using descriptive statistics and histograms to visualize distribution. Figure 2-3 below visualize the distributions of variables using histograms, while Table 1 provides descriptive statistics for the variables.
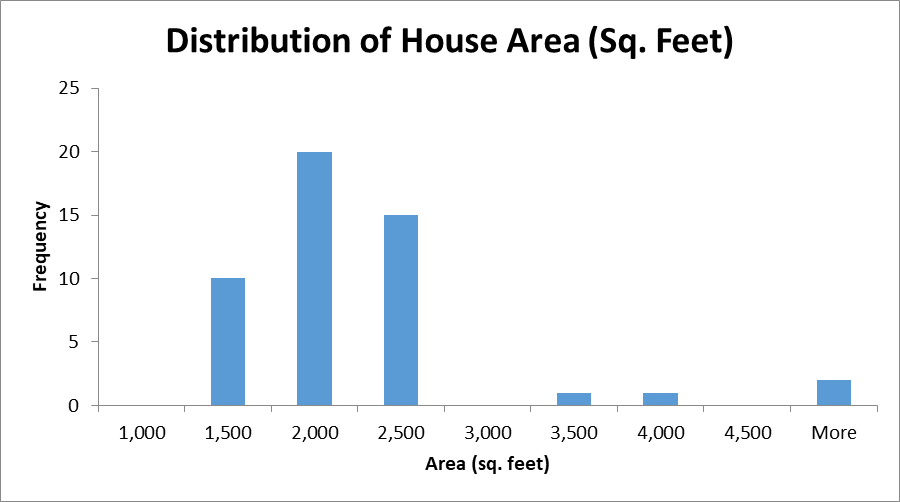
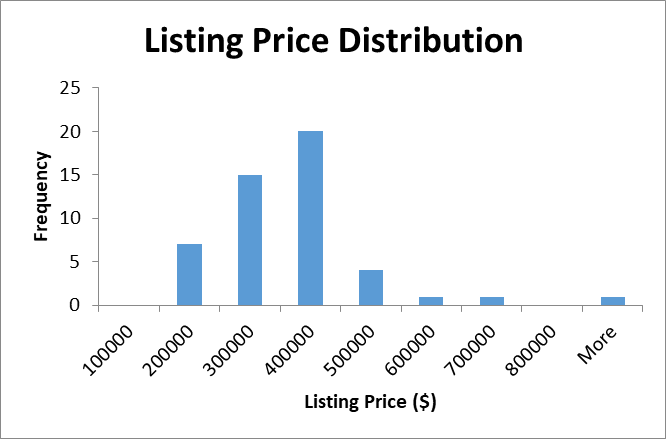
The analysis of the distribution demonstrated that the distributions of the listing prices and square footage were heavily right-skewed. Moreover, there were significant gaps between the clusters of data. Most data points for listing prices were scattered between $100,000 and $500,000, while most data points for square footage varied between 1,500 feet and 2,500 feet. The mean value might have been impacted by the outliers.
The average square footage of the houses in the sample was 2,005 with a standard deviation of 836 and a median value of 1,798. The average listing price was $327,239 with a standard deviation of 120,401 and a median of $313,300. The comparative analysis demonstrated that the sample was representative of the population as the descriptive statistics of the sample were close to the descriptive statistics of the population.
Develop Regression Model
A scatterplot with a line of best fit was created to demonstrate the relationship between the variables. The scatterplot is provided in Figure 4 below.
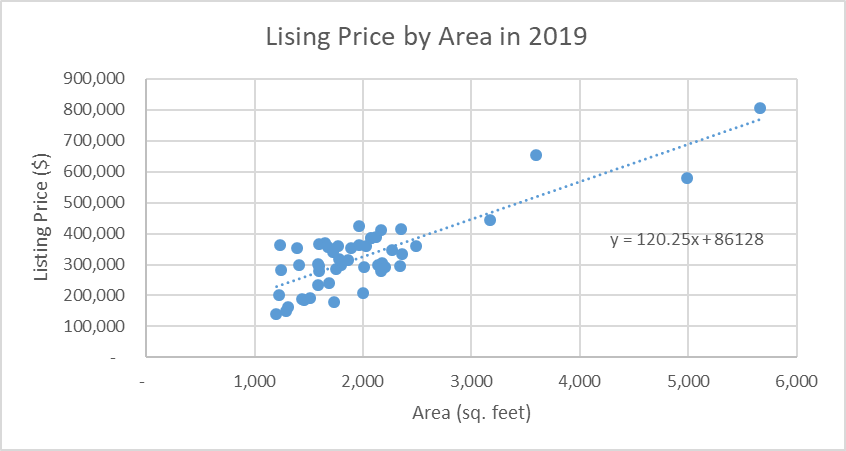
The trendline is ascending and the datapoints are scattered around the trendline equally above and below. The angle of the regression line is close to 45 degrees, which demonstrates a very strong positive correlation. This implies that the higher the area of the house the higher is the listing price of the house. Although there were some outliers in the model, it is better to maintain them since they provide valuable information about the larger-than-normal dwellings. Pearson’s correlation coefficient (Pearson’s r) was 0.84, which confirms that the correlation between the variables was very strong.
Determine the Line of Best Fit
The regression analysis demonstrated that the listing price can be predicted using the following equation:
Price = 86,128 * 120.25 * Area
Where Price stands for the listing price of a house in 2019 and Area is the square footage of the house.
The equation demonstrates that a minimal price of a house with an area 0 sq. feet is $86,128 and the price increases by $120.25 with an increase of area by 1 sq. foot. The coefficient of determination (R2) was 0.7, which demonstrate that 70% of the variation in the listing price can be explained by the variation in the area of the house. The equation can be used for creating a benchmark price for a house. For instance, if a house’s area is 1,500 sq. feet, the listing price will be $266,503. The calculations are demonstrated below:
Price = 86,128 * 120.25 * 1,500 = 266,503
Conclusions
The results of the analysis demonstrated that the listing price of houses was highly dependent on the area of the houses. The created model can be used to create a benchmark price for listing the houses, which was the expected outcome of this report. However, it should be noted that the created model could explain only 70% of the variation in the listing price. Therefore, there are other variables that affect the listing price. Thus, future research should focus on answering the questions of what variables other than the area of the house affect the listing price of the house.
